Parcours d’arbre : Depth First & Breadth First 🌳
Parcours d’arbre : Depth First & Breadth First
Le parcours d’arbre est un grand classique lors d’entretiens algorithmiques et bien que cet exercice peut sembler intimidant au premier abord, nous allons découvrir qu’il y a, en réalité, plus de peur que de mal !
Ainsi, dans cet article, nous nous intéressons aux deux méthodes les plus courantes afin de parcourir un arbre que sont :
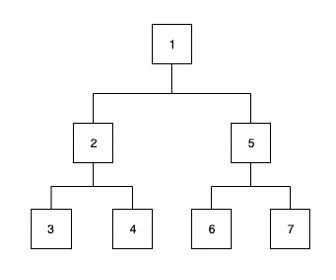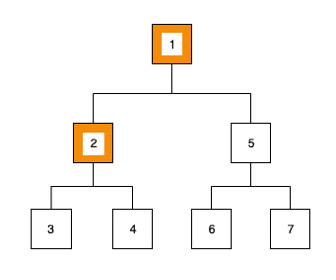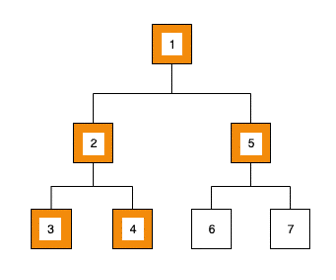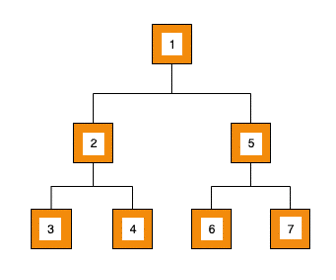
- le parcours en profondeur (Depth First), où le choix du prochain noeud se porte sur le premier enfant du noeud courant :
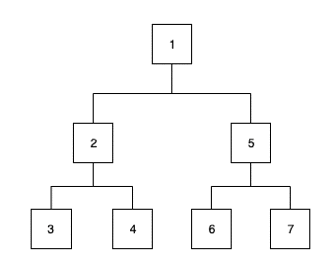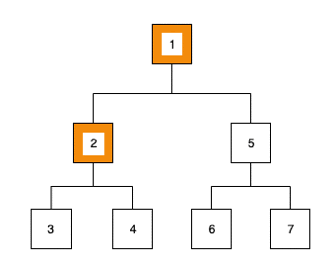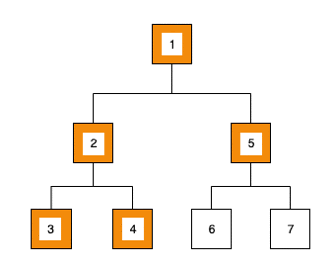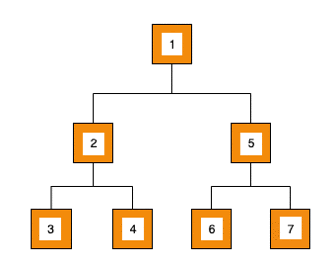
Parcours en profondeur
- le parcours en largeur (Breadth First), où le prochain noeud est celui adjacent au noeud courant, c’est-à-dire celui situé au même niveau de profondeur :
Parcours en largeur
Parcours en profondeur - Depth first
Au niveau algorithmique, l’utilisation de la récursivité reste le choix le plus pertinent. Ainsi, nous utiliserons la récursivité pour notre parcours mais nous y ajouterons toutefois une étape supplémentaire pour les besoins de l’article, en stockant les noeuds dans une structure de données.
En effet, dès l’entrée dans un noeud et après le traitement de sa valeur, nous stockerons ses enfants dans une structure de données (contenant une méthode saveNode), récupérerons ensuite le prochain noeud (méthode getNextNode) et passerons à la prochaine étape de notre parcours. En pseudo-code, nous obtenons ainsi :
// Structure de données encore inconnue
class Structure {
saveNode(node) {}
getNextNode() {}
}
// Fonction de traitement d'un noeud
var nodeStructure = new Structure()
function computeNode(node) {
if(!node) return;
computeNodeValue(node.value)
if(node.left) nodeStructure.saveNode(node.left)
if(node.right) nodeStructure.saveNode(node.right)
computeNode(nodeStructure.getNextNode())
}
// Création de l'arbre et début du parcours
var tree = new Tree(...)
computeNode(tree.root)
Maintenant, si nous déroulons un exemple plus concret avec l’arbre présenté en début d’article et le pseudo-code ci-dessus :
1ère étape :
- Nous traitons la valeur du noeud : 1, nous sommes à la racine
- Nous ajoutons ses deux enfants dans la structure de données :
[2,5] - Nous récupérons le prochain élément :
[2,5]=> 2,[5]
2ème étape :
- Nous traitons la valeur du noeud : 2
- Nous ajoutons ses deux enfants dans la structure de données :
[3, 4, 5] - Nous récupérons le prochain élément :
[3, 4, 5]=> 3,[4,5]
3ème étape :
- Nous traitons la valeur du noeud : 3
- Pas d’enfant, la structure est inchangée :
[4, 5] - Nous récupérons le prochain élément :
[4, 5]=> 4,[5]
4ème étape :
- Nous traitons la valeur du noeud : 4
- Pas d’enfant, la structure est inchangée :
[5] - Nous récupérons le prochain élément :
[5]=> 5,[]
5ème étape :
- Nous traitons la valeur du noeud : 5
- Nous ajoutons ses deux enfants dans la structure de données :
[6,7] - Nous récupérons le prochain élément :
[6,7]=> 6,[7]
6ème étape :
- Nous traitons la valeur du noeud : 6
- Pas d’enfant, la structure est inchangée :
[7] - Nous récupérons le prochain élément :
[7]=> 7,[]
7ème étape :
- Nous traitons la valeur du noeud : 7
- Pas d’enfant, la structure est inchangée :
[] - Nous récupérons le prochain élément :
[]=> x,[]
8ème étape :
- Pas de valeur et la structure est vide : le parcours est terminé
Après ce long déroulé, nous constatons que l’ordre d’ajout dans la liste à son importance : nous ne prenons que le noeud inséré le plus récemment. En algorithmique, ce concept est appelé Last In First Out, abrégé LIFO, et notre structure de données doit respecter cette règle pour devenir compatible avec le parcours en profondeur; comme par exemple une stack.
Un ajustement s’avère néanmoins nécessaire vis-à-vis du pseudo-algorithme précédent : le noeud gauche y est inséré avant le noeud de droite. On parcourt ainsi l’arbre par la droite (1 -5 - 7 - 6 - 2 - 4 - 3) et on doit ainsi permuter les deux lignes saveNode :
// Noeud droite avant le gauche
if (node.right) nodeStructure.saveNode(node.right);
if (node.left) nodeStructure.saveNode(node.left);
Nous en avons ainsi fini avec le parcours en profondeur. L’ajout d’une structure de données peut sembler au premier abord superflu mais, rassurez-vous, ce socle nous sera très utile pour le parcours en largeur.
Parcours en largeur - Breadth First
Pour le parcours en largeur, nous utiliserons une base identique à celle du parcours en profondeur, à savoir le pseudo-algorithme associé à une structure de données (encore inconnue à ce stade).
Si, comme précédent, nous effectuons un déroulé des différentes étapes du parcours, nous obtenons :
1ère étape :
- Nous traitons la valeur du noeud : 1, nous sommes à la racine
- Nous ajoutons ses deux enfants dans la structure de données :
[2,5] - Nous récupérons le prochain élément :
[2,5]=> 2,[5]
2ème étape :
- Nous traitons la valeur du noeud : 2
- Nous ajoutons ses deux enfants dans la structure de données :
[3, 4, 5] - Nous récupérons le prochain élément :
[3, 4, 5]=> 5,[3, 4]
3ème étape :
- Nous traitons la valeur du noeud : 5
- Nous ajoutons ses deux enfants dans la structure de données :
[3, 4, 6, 7] - Nous récupérons le prochain élément :
[3, 4, 6, 7]=> 3,[4, 6, 7]
4ème étape :
- Nous traitons la valeur du noeud : 3
- Pas d’enfant, la structure est inchangée :
[4, 6, 7] - Nous récupérons le prochain élément :
[4, 6, 7]=> 4,[6, 7]
5ème étape :
- Nous traitons la valeur du noeud : 4
- Pas d’enfant, la structure est inchangée :
[6,7] - Nous récupérons le prochain élément :
[6,7]=> 6,[7]
6ème étape :
- Nous traitons la valeur du noeud : 6
- Pas d’enfant, la structure est inchangée :
[7] - Nous récupérons le prochain élément :
[7]=> 7,[]
7ème étape :
- Nous traitons la valeur du noeud : 7
- Pas d’enfant, la structure est inchangée :
[] - Nous récupérons le prochain élément :
[]=> x,[]
8ème étape :
- Pas de valeur et la structure est vide : le parcours est terminé
Ici, et contrairement au parcours en profondeur, ce n’est pas le dernier noeud inséré qui nous intéresse mais le plus ancien. Ce concept algorithmique, appelé First In First Out et abrégé FIFO, se doit donc d’être respecté par notre structure de données et comme exemple, nous pouvons citer une queue, cette dernière étant similaire à une file d’attente.
Conclusion
Plusieurs domaines de l’informatique exploitent la puissance des arbres : index de base de données, arbres de décision, analyse de code source (Abstract syntax tree)… et cela explique ainsi leur présence en entretien technique.
Toutefois comme nous venons de le voir, le parcours d’arbre en profondeur ou en largeur n’est pas si complexe et peut se résumer à une simple association avec une structure de données :
- une structure respectant la logique LIFO pour un parcours en profondeur
- et une structure respectant la logique FIFO pour un parcours en largeur
Deux concepts finalement faciles et rapides à retenir et qui, j’espère, ne vous fera plus craindre de futurs entretiens avec des parcours d’arbres !